
背景
当前Presto集群无法承载用户的请求量,用户经常抱怨查询慢或者超时。我们前期通过扩容节点可以提升集群的吞吐,但是后期扩容节点后,集群的吞吐没有,随之而来的是,集群稳定性下降(Presto是MPP架构,一个节点异常,所有在这个节点的查询都失败,所有节点数增加,单节点异常的概率增加)。
分析
吞吐量上不去,从三个方面来看,集群资源层,集群服务本身以及用户的SQL。
首先查看用户的SQL,发现用户查询的表数据分布均衡,每个节点的数据量分布没有非常大的差异。 其次查看用户的SQL,查询使用了索引,数据jion也正常,没有笛卡尔积的现象
其次查看服务本身配置,查询业界相对应的集群配置,没有发现明显的异常
首先从资源层面分析,资源我们经常考虑的是CPU、内存、磁盘和网络。查看对应的Pod资源监控,发现CPU、内存、磁盘使用率相对处于正常范围,没有达到瓶颈,查看网卡带宽,发现Pod把网络带宽(10Gb)打满
因此,我们定位问题的根因是网络带宽瓶颈。思考一下,因为Presto 在并行查询的时候,会把数据分布多个worker节点,每个节点独立执行自己的数据子集,当需要进行shuffle join,聚合和排序操作的时候,presto会交换数据。交换数据会使用Pod网络,加上我们部分查询的数据量确实比较大,高峰期大并发情况网络是很大概率被打满的。至于说再扩容节点,那你在进行聚合的时候,数据会在一个节点执行,那么这个节点的网络总是会成为瓶颈。
解决方案:
因为我对云原生研究的比较多,思考利用云原生的特性去解决,deployment是一个解决思路。那么每个业务采用多个deployment是不是就可以了? 每个deployment是固定的节点,而且可以固定并发,当业务吞吐上升的时候,我直接扩容一个deployemnt。有了这个思路,我们就可以重新优化Presto的架构了。
问题一
Presto 是一种分布式 SQL 查询引擎,旨在查询分布在一个或多个异构数据源上的大型数据集。架构有两个角色,分布是Coordinator和Worker,Coordinator负责查询计划和状态服务,Worker负责查询。我们做一个定义,1个Coordinator和多个worker组成一个集群。
根据上述的推导,我们可以使用扩展多个set来代替之前一个set,解决一个set吞吐不足的问题
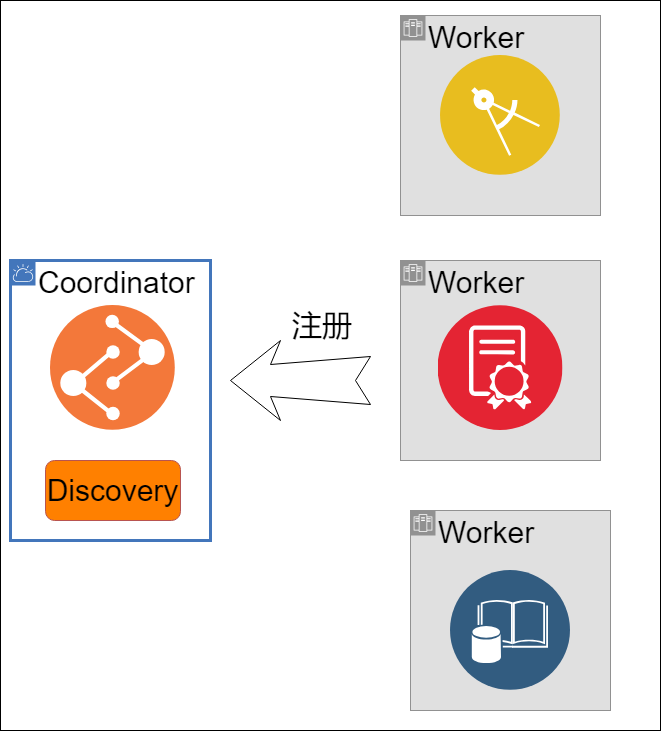
第一个问题是Worker注册Coordinator的问题。背景是因为成本的因素,我们的Coordinator和Worker是部署在两个不同的K8S集群。所以两个K8s的POD之间的容器网络不通,只能使用Host Network。使用Host Network就会导致Cooordinator端口不能是固定的,只能是随机的。
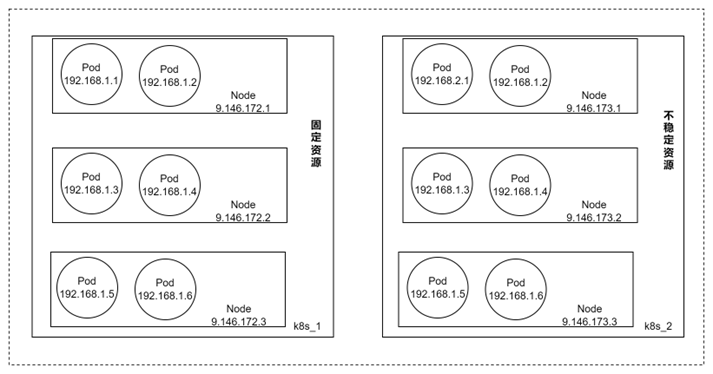
因此Worker如何发现Coordinator的IP和端口成为关键
老架构使用的是CLB挂载Coordiantor,worker直接使用Coordinator的IP和端口作为注册URL。简化了注册过程。但是我们如果要部署多个set,提前申请多个CLB,从成本来看,比较浪费,如果是动态申请,则影响集群的启动时间,特别是后续我们实现自动扩缩容,我们都是要求2分钟内启动一个新的set。
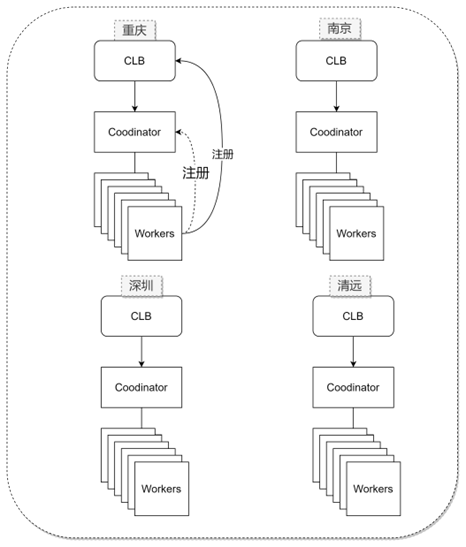
我们也调研了其他的方案,比如k8s的service,很可惜,不同k8s 的service也不能联通。使用中间件,redis或者mysql,把coordinate和worker信息存入,但是测试过程中发现写入失败的情况,而且也不轻量化。
最终经过我们推导,要想使用一个固定的随机端口,那么我们可以使用deployment的name的公共部分,有了公共字符串,那么Hash就可以获取一个固定端口。通过域名 + Hash(Port)的方式,我们解决了注册问题。之后我们可以轻量化的扩容或者缩容set。
问题二
第二个问题 有了轻量化的多个set,我们就需要负载均衡,我们使用了业界常用的presto-gateway。相对于传统的nginx,presto-gateway支持动态加载配置,支持API更新集群。那么我们可以在启动停止脚本动态的新增集群和卸载集群。
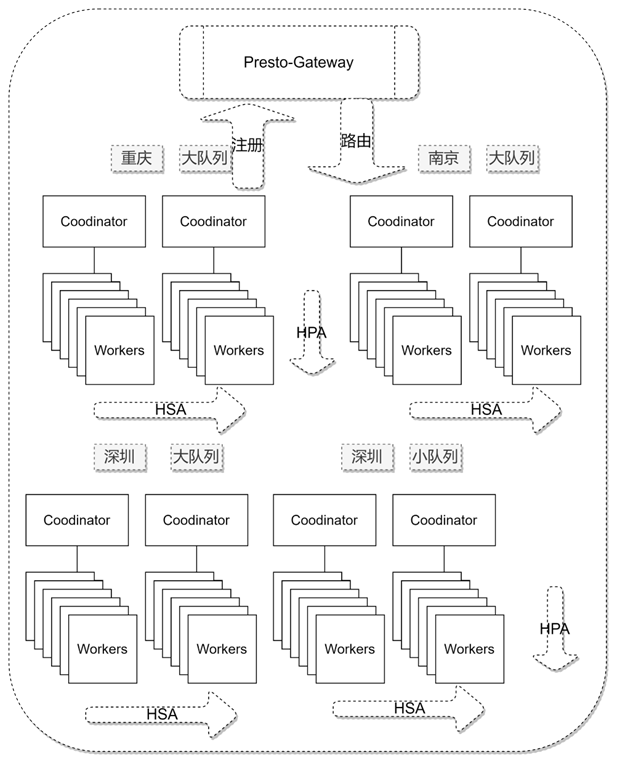
讲到这里,引入了一个新问题,我们如何保障集群graceful shutdown,即集群停止时把当前集群的任务执行完。我们利用率k8s preStop hook 先发送shutdown信号到presto节点,presto节点不再接受新的请求 ,然后我们定时检测Coordinator的任务接口,查看当前是否有运行的查询,如果没有运行查询,我们直接exit。如果有,我们循环等待,直至时间达到k8s TerminationGracePeriodSeconds。
问题三
有了presto-gateway和轻量化的集群,我们可以很容易通过增加set提升集群的吞吐,但是引入第三个问题,成本。当前如果保留过多的set,可以满足更多的吞吐,但是资源利用率底,特别时夜间,几乎没有查询,相对来说比较浪费。所以我们可以结合k8s的HPA思路来实现动态伸缩的能力。因为我们时set为基本单位,k8s的HPA无法满足我们的需求,因此我们实现了基于HSA的动态伸缩。实现了资源水位管控、异常情况识别、配额管理以及亲和配置,保障资源的高效利用。
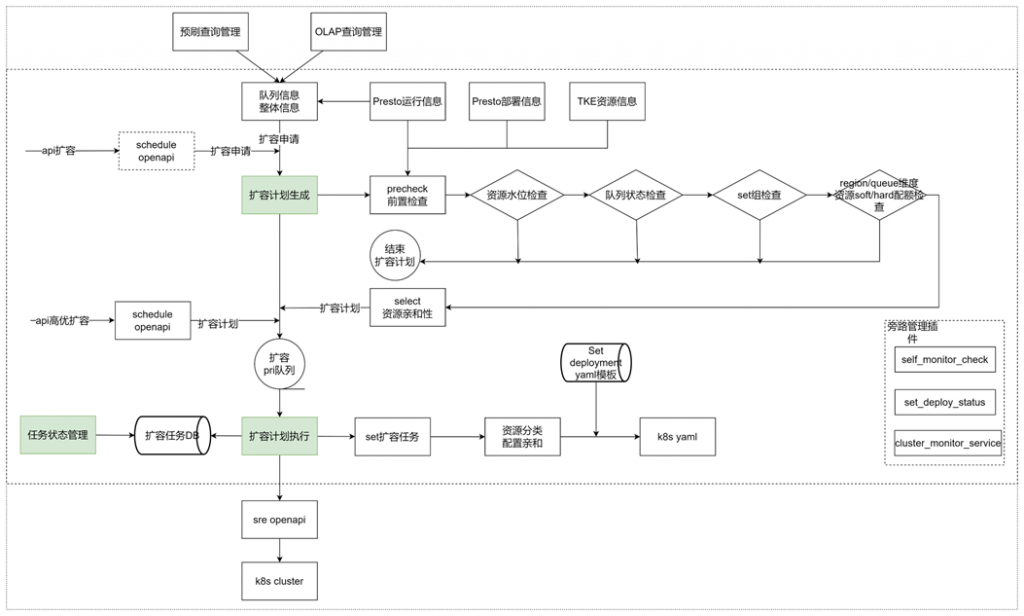
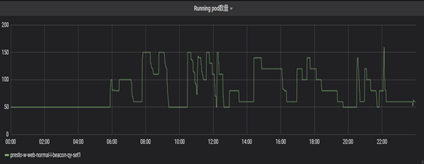
为了更加极致的资源利用,当我们保留一个set的时候,我们也实现了基于运行数和排队数的HPA能力,提升了资源极致的利用率。
问题四
现在我们的集群可以高吞吐、低成本的运行,但是我们观察集群的整体成功率和耗时,整体来说,相对比较差。经过分析,我们发现查询中90%时小查询,一般30s左右就可以执行完成, 但是因为部分大查询的资源占用,导致小查询等待,延迟了整体的查询时间。基于此,我们根据HDFS的扫描量进行了查询的拆分,低于1G时小查询,大于1G的大查询,通过拆分大小队列,我们集群的整体耗时直接降下来,成功率由90%提升到99%。耗时小查询从200下降到30s,大查询时240s。
后续运营过程中,我们发现了特大查询超出了我们系统边界,我们采用了查询预拦截、旁路黑名单、实时kill提前拦截了相应的查询,并推送用户优化,以及相关的基础优化建议。
成果
经过此次优化,我们集群整体的吞吐量提升了3倍的情况下,成功率提升到99%,耗时小查询从200下降到30s,大查询时240s。开发了动态伸缩系统,成本节约50%